
— Publié le 16 juin 2018 —
On parle de contenu dupliqué (duplicate content) quand un contenu apparaît plus d’une fois sur internet. La notion « plus d’une fois » se base sur les URLs des pages : si un contenu apparaît sur plus d’une URL, alors on a du contenu dupliqué.
Cela peut se produire au sein de votre propre site, dans ce cas, on parle de contenu interne ou intrasite. Ou alors sur un autre site, dans ce cas, on parle de contenu externe ou extrasite et cela peut déboucher sur du plagiat ou du vol de contenu, donc attention.
Les conséquences du contenu dupliqué
Il s’agit de distinguer 2 points de vue : le contenu dupliqué vu par les moteurs de recherche et le contenu dupliqué vu par les propriétaires de sites web.
Vue des moteurs de recherche
Le contenu dupliqué pose 3 problèmes aux moteurs de recherche.
- Ils ne savent pas quelle(s) version(s) inclure ou exclure de leur index.
- Ils ne savent pas s’ils doivent diriger les attributs des liens (trust, authority, anchor text, link equity…), vers une seule page ou les séparer entre les différentes versions.
- Ils ne savent pas quelle(s) version(s) positionner dans les résultats de recherche
Le contenu dupliqué va avoir une influence sur l’indexation des pages d’un site dans les moteurs de recherche, sans pour autant, à ce stade, générer de pénalités. Mais les algorithmes savent le détecter et peuvent décider de faire chuter dans les résultats de recherche la page incriminée car leur but est d’apporter la meilleure réponse à un internaute tapant une requête dans un moteur donc présenter plusieurs fois la même chose n’est pas pertinent.
Vue des propriétaires de sites
Là, on touche un sujet plus sensible. Le contenu dupliqué peut provenir d’un vol de contenu, c’est à dire quelqu’un qui copie / colle purement et simplement votre contenu dans son site. Le plagiat évident est sévèrement puni par Google. Ceux qui le font risquent :
- La rétrogradation des pages dans les résultats de recherche.
- La disparition complète du site dans les résultats de recherche.
Vous voyez qu’en plus d’un impact sur votre crédibilité de votre site, considéré comme un copieur, vous pouvez perdre gros avec Google, donc soyez vigileants.
Si c’est votre site qui a été copié et pénalisé (Google ne sachant pas qui a copié qui), vous pouvez demander un examen manuel à Google afin de faire réindexer votre site, à condition de pouvoir prouver l’antériorité et la paternité de votre contenu.
Si vous avez envie de regarder si quelqu’un a volé votre contenu, nous vous proposons 3 outils gratuits. Vous saisissez un morceau de texte ou une URL et voyez si plusieurs URLs présentent ce contenu :
Si c’est le cas, vous pouvez le signaler à Google en utilisant cette URL : support.google.com/legal
Dernier conseil, si vous embauchez une agence ou un rédacteur pour rédiger vos contenus, assurez-vous que votre contrat contient bien la rédaction de contenu 100% exclusif et que c’est bien le cas !
Cas de contenu dupliqué
La plupart du temps, le contenu dupliqué n’est pas généré intentionnellement. Cependant, on estime à 1/3 les sites qui ont du contenu dupliqué. Voici quelques exemples fréquents :
URLs avec paramètres
On trouve souvent ce cas dans les boutiques e-commerce, dans les blogs avec certains CMS et avec les outils de tracking. Un même contenu peut être accessible via plusieurs URLs qui ont des paramètres différents ou dans un ordre différent. Voici 2 exemples :
- www.maboutique.com/jupes?color=bleu&cat=3 est un doublon de www.maboutique.com/jupes?cat=3&color=bleu
- www.blog.com/titre_article est un doublon de www.blog.com/category/titre_article
On peut également avoir le cas lorsque des ID de sessions sont stockés dans l’URL.
A retenir : dans la mesure du possible, essayer de ne pas passer de paramètres dans vos URLs.
Accès à votre site avec et sans www
Un cas très fréquent de contenu dupliqué est induit par une mauvaise gestion de votre site avec et sans les www. Par exemple, www.yesyouweb.com et yesyouweb.com. Mais également entre les versions http et https de votre site.
Pour éviter cela, utilisez à bon escient les redirections 301.
Copie de contenus
Intentionnels ou non, évitez de copier / coller le même texte dans plusieurs pages de votre site ou venant de sites extérieurs. Si vos produits sont vendus dans plusieurs boutiques avec des descriptions identique, nous allons voir comment utiliser des URLs canoniques.
Lancement d’un nouveau site
Vous venez de refaire votre site internet ou de le restructurer : vos URLs ont un nouveau format et vous avez des contenus similaires à l’ancien site. N’oubliez pas de faire vos redirections d’URLs pour indiquer cette refonte à Google et aussi éviter que les internautes ne tombent sur des erreurs 404 avec vos anciennes URLs.
Résoudre les problèmes de contenu dupliqué
La résolution des problèmes de contenu dupliqué tourne autour d’une seule idée : comment indiquer à Google quelle est la « bonne » URL. Il y a 3 méthodes pour cela dont nous avons déjà un peu parlé précédemment :
Les redirections 301
La redirection 301 est une redirection de la page dupliquée vers la page « officielle ». Avec cette méthode, la page dupliquée n’existe plus par elle-même : si un internaute tape son URL dans la barre du navigateur, l’URL de la page officielle s’affichera automatiquement.
Il y a différentes méthodes pour y parvenir selon les cas mais vous pouvez consulter notre article sur le sujet : Comment faire des redirections d’urls via le fichier .htaccess.
Les URLs canoniques
Les URLs canoniques permettent de conserver les pages dupliquées mais d’indiquer dans leur code qu’elles sont similaires à une page officielle. Vous voyez la nuance avec les redirections ! Si vous voulez tout savoir sur les URLs canoniques, nous avons également un article sur le sujet : Pourquoi utiliser des urls canoniques.
La balise meta Noindex
Grâce à cette balise à mettre dans la partie head de votre code html, vous pouvez indiquer à Google de ne pas indexer une page dupliquée. Voilà ce que vous devez y mettre :
On autorise Google à parcourir les liens contenus (follow) dans la page mais pas à l’indexer (noindex). Il est important de laisser Google la parcourir sinon vous allez l’inquiéter.
Déclarer le site dans Search Console
Search Console vous permet déjà de repérer du contenu dupliqué au sein de votre site. Pour ce faire, allez dans Améliorations html :
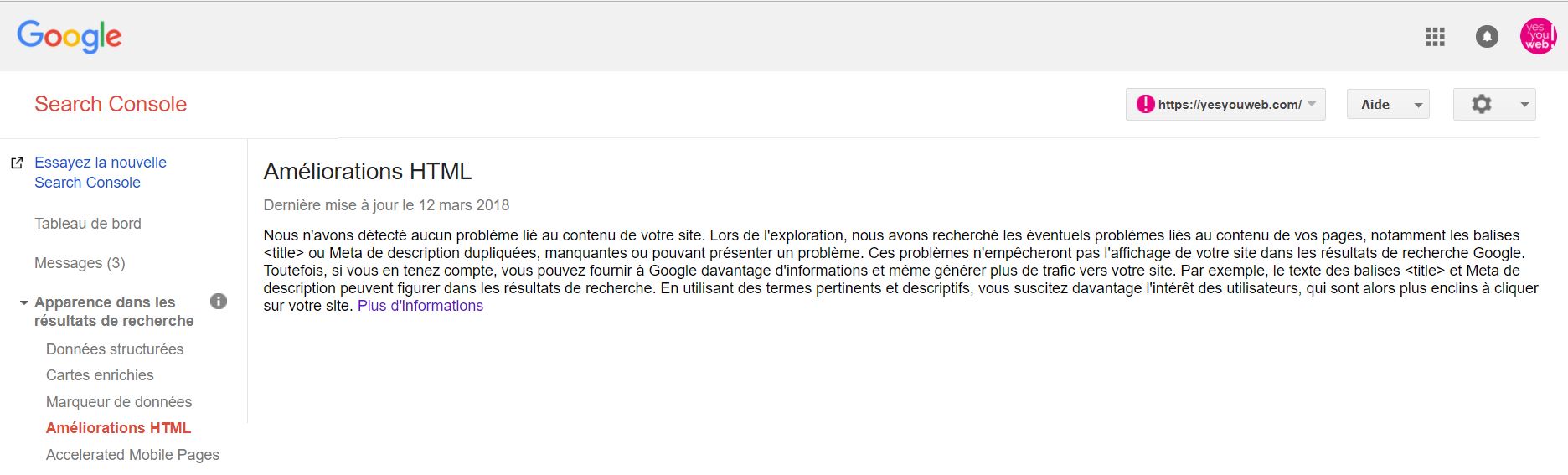
Vous pouvez également déclarer votre site principal. Pour ce faire, cliquez en haut à droite sur la roue crantée puis sur Paramètres du site :

Conclusion
Voilà, nous espérons que cet article vous aura permis de mieux comprendre le sujet du contenu dupliqué.
Si vous avez des questions, posez-les en commentaires ci-dessous.
Et n’hésitez pas à partager vos propres retours d’expérience !
Laisser un commentaire